Рис. 16.1. Взвешенный граф
Богатая коллекция структур данных, основанная на использовании шаблонов, недавно была добавлена к стандартной библиотеке языка C++. Эти структуры содержат классы для векторов, списков, множеств, карт (словарей), стеков, очередей, очередей с приоритетами. Когда этот стандарт станет распространен повсеместно, программисты на языке C++ будут освобождены от необходимости постоянно переопределять и повторно реализовывать один и тот же набор классов для структур данных. Более подробная информация о библиотеке STL (STL — Standard Template Library, стандартная библиотека шаблонов) может быть найдена в работах [Musser 1996, Glass 1996].
Создание STL является результатом многолетних исследований под руководством Александра Степанова и Менга Ли из компании Hewlett-Packard и Дэвида Мюссера из Rensselaer Polytechnic Institute. Создание STL вдохновлялось не только предшествующими объектно-ориентированными библиотеками, но и многолетним опытом работы ее создателей в области функциональных и директивных языков программирования (Scheme и Ada).
Одна из наиболее необычных идей в STL — это обобщенные алгоритмы. Она заслуживает отдельного рассмотрения, поскольку выглядит вызовом объектно-ориентированным принципам, которые мы обсуждали до сих пор, и в то же время является источником огромной мощи библиотеки STL. Обобщенные алгоритмы в STL напоминают классы-шаблоны. Идея шаблонов применяется к отдельным функциям. Чтобы понять концепцию обобщенных алгоритмов, мы сперва должны описать использование инкапсуляции в большинстве объектных библиотек.
Объектно-ориентированное программирование рассматривает инкапсуляцию как главную цель. Хорошо разработанный объект старается инкапсулировать все состояние и поведение, необходимые для выполнения задачи, и в то же время скрывает как можно больше деталей внутреннего устройства. Во многих предшествующих объектно-ориентированных библиотеках этот философский подход воплощался в контейнерных классах, обладающих широкой функциональностью и богатым интерфейсом.
Разработчики STL пошли в совершенно другом направлении. Поведение, обеспечиваемое их стандартными компонентами, является минимальным, почти что спартанским. Вместо этого каждый компонент предназначен для функционирования совместно с большим набором обобщенных алгоритмов, имеющихся в библиотеке. Эти алгоритмы не зависят от контейнеров и поэтому могут работать со многими различными типами.
Отделяя функционирование алгоритмов от контейнерных классов, библиотека STL много выигрывает в размере — как в объеме самой библиотеки, так и в генерируемом коде. Вместо того чтобы дублировать алгоритмы для дюжины или около того контейнерных классов, одно-единственное описание библиотечной функции может использоваться с любым контейнером. Более того, описание этих функций является настолько общим, что они могут применяться с обычными массивами и указателями (в смысле языка C), и с другими типами данных.
Наш пример проиллюстрирует некоторые основные свойства стандартной библиотеки шаблонов. Обобщенный алгоритм find находит первое вхождение заданного значения в коллекцию. Итераторы стандартной библиотеки состоят из пар значений, отмечающих начало и конец структуры. Алгоритм find использует пару итераторов и ищет первое вхождение заданного значения. Он определен следующим образом:
|
Алгоритм будет работать со структурой любого типа, в том числе и с обычными массивами языка C. Чтобы найти первое вхождение числа 7 в массив целых, пользователь выполняет следующий код:
|
Поиск первого значения в целочисленном списке ничуть не сложнее:
|
В этой главе мы можем описать только основные свойства STL. Следующие два раздела посвящены базовым концепциям, используемым в библиотеке, а именно итераторам и объектам-функциям. Затем три примера проиллюстрируют в действии контейнеры и обобщенные алгоритмы библиотеки STL.
Итераторы — это фундамент, на котором основано использование контейнерных классов и соответствующих алгоритмов из стандартной библиотеки. Абстрактно итератор — это просто объект типа указателя, который применяется для прохода по всем элементам в контейнере.
Подобно тому как указатели по-разному используются в традиционном программировании, итераторы применяются для различных целей. Итератор может обозначать конкретное значение (как указатель указывает на конкретную область памяти). С другой стороны, пара итераторов может задавать диапазон значений (два указателя отмечают границы непрерывного участка памяти). Однако в случае итераторов описываемые значения расположены друг за другом не физически, а логически. Это происходит, поскольку они взяты из одного контейнера и, следовательно, следуют друг за другом в том порядке, как они хранились в контейнере.
Традиционные указатели иногда принимают значение null — то есть не указывают ни на что. Итераторы аналогичным образом могут не определять какое-либо конкретное значение. Подобно тому, как логической ошибкой является разыменование и использование указателя со значением null, нельзя разыменовывать и применять итератор, который не определяет никакого значения.
Когда в языке C++ используются два указателя, которые ограничивают область памяти, по соглашению второй указатель не рассматривается как часть области. Например, массив с именем x и длиной 10 иногда описывается как занимающий область от x до x+10, хотя элемент x+10 не является частью массива. На самом деле указатель x+10 ссылается на запредельный элемент, то есть элемент, следующий за последним элементом описываемого диапазона. Итераторы определяют диапазон аналогичным образом. Второе значение рассматривается не как часть определяемого диапазона, но как запредельный элемент, описывающий значение, следующее в последовательности за последним значением из заданного диапазона.
Подобно традиционным указателям, основное действие, которое модифицирует итератор, это инкрементация (оператор ++). Когда инкрементация применяется к итератору, который указывает на последнее значение в последовательности, итератор принимает описанное выше запредельное значение. Оператор разыменования (*) осуществляет доступ к данным, определяемым итератором.
Диапазон может описывать весь контейнер при задании итератора, указывающего на первый элемент, и итератора, имеющего специальное «последнее» значение. Диапазоны могут описывать подпоследовательности, входящие в контейнер (двум итераторам присваиваются конкретные значения). В стандартных контейнерах итератор начала контейнера возвращается функцией begin(), а итератор, обозначающий конец контейнера, — функцией end().
Ряд обобщенных алгоритмов из библиотеки STL требует функций в качестве аргументов. Простым примером служит обобщенный алгоритм for_each(), который вызывает функцию, переданную в качестве аргумента, для каждого значения в контейнере. Следующий код используется для того, чтобы вывести полный набор значений в целочисленном списке:
16.1. Итераторы
16.2. Объекты-функции
|
Понятие функции было обобщено до понятия объекта-функции. Объект-функция — это экземпляр класса, в котором определен метод «круглые скобки» (). В ряде случаев удобно заменить функции на объекты-функции. Когда объект-функция используется в качестве функции, то при ее вызове используется оператор «круглые скобки».
Чтобы проиллюстрировать это, рассмотрим следующее определение класса:
|
Если мы создадим экземпляр класса biggerThanThree, то каждый раз, когда мы будем ссылаться на него с использованием синтаксиса вызова функции, будет вызываться метод, соответствующий оператору «круглые скобки». Следующий шаг — обобщить этот класс, добавив к нему конструктор и неизменяемое поле данных, которое устанавливается конструктором:
|
Результатом является функция общего вида, выполняющая целочисленное сравнение «больше чем X», где значение X определяется при создании экземпляра класса. Это может быть сделано, например, при передачи одной из обобщенных функций аргумента — логической функции. Мы ищем в списке первое значение, большее 12, с помощью кода
|
Наш первый пример иллюстрирует создание и обработку объектов в библиотеке STL. Допустим, фирме WorldWideWidgetWorks потребовалась программа учета виджетов. Виджеты — это простые устройства, различаемые по идентификационным номерам:
|
Инвентарь описывается двумя списками. Один представляет собой виджеты, имеющиеся в данный момент на складе. Второй список содержит типы виджетов, которые были заказаны покупателями. Первый список содержит собственно виджеты, а второй — идентификационные типы виджетов. Чтобы управлять инвентарем, требуются две команды:
|
Когда поступает новый виджет, мы сравниваем его идентификационный номер со списком заказанных виджетов. Мы используем функцию find() для поиска в списке заказов и немедленно пересылаем виджет покупателю, если он (виджет) был заказан. В противном случае он добавляется к списку виджетов на складе.
|
Когда покупатель заказывает новый виджет, мы просматриваем с помощью функции find_if() список имеющихся на складе виджетов, чтобы определить, нельзя ли обслужить заказ немедленно. Для этого определена унарная функция, которая берет в качестве аргумента виджет и определяет, соответствует ли он требуемому типу. Эта функция записывается следующим образом:
|
Функция, обслуживающая заказы виджетов, выглядит так:
|
Второй и третий примеры используют тип данных «карта». Карта map — это индексированный словарь, то есть набор пар ключ-значение.
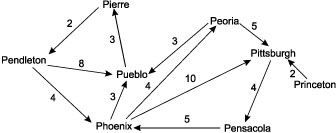
Карта, в которой элементами тоже являются карты, служит естественным представлением направленного графа. Предположим, к примеру, что мы используем текстовые строки для кодирования названий городов и хотим сконструировать карту, где значения ребер графа — это расстояние между двумя соответствующими городами. Такой граф показан на рис. 16.1.
Рис. 16.1. Взвешенный граф
Листинг 16.1.
Операторы инициализации графа
|
Тип данных stringVector — это вектор целых чисел, индексированный строками. Тип данных graph — это двумерный разреженный массив, индексированный строками и содержащий целые числа. Последовательность операторов присваивания инициализирует граф. Граф, показанный на рис. 16.1, реализован в листинге 16.1.
Можно использовать набор классических алгоритмов для обработки таких графов. Одним из примеров является алгоритм Дейкстры поиска кратчайшего пути. Требуется указать город, с которого начинается путь. При этом создается приоритетная очередь для пар расстояние/город. Она инициализируется нулем для начального города. Приоритетная очередь содержит города в порядке от ближайшего до самого дальнего. Определение типа данных DistancePair выглядит следующим образом:
|
При каждой итерации цикла мы извлекаем из очереди город. Если для него еще не найдено кратчайшего пути, записывается текущее расстояние и путем проверки графа вычисляется расстояние до соседних городов. Этот процесс продолжается до тех пор, пока не будет исчерпана приоритетная очередь.
|
Последним примером является алфавитный указатель. Программа использует связные списки и тип данных multimap. multimap — это разновидность карт, которая позволяет индексировать одним ключом несколько данных.
Алфавитный указатель представляет собой список упорядоченных по алфавиту слов, который показывает номера строк, где встречается то или иное слово. Эти значения хранятся в алфавитном указателе в виде мультикарты multimap, индексированной словами (тип данных string). Ее содержимое — целые числа (номера строк в тексте). Мультикарта используется потому, что одно и то же слово встречается в нескольких местах. На самом деле обнаружение таких повторений — главное предназначение алфавитного указателя.
Тип данных для алфавитного указателя задается следующим образом:
|
Создание алфавитного указателя разбивается на два шага. Сперва он генерируется программой (строки текста считываются из входного потока), а затем результат печатается в выходной файл. Эти два шага реализуются в функциях-членах readText() и printConcordance(). Первая из них записывается следующим образом:
|
Строки текста считываются из входного потока одна за другой. Их текст прежде всего преобразуется к нижнему регистру. Затем строка разбивается на слова с помощью функции split(). Набор литер-разделителей и исходный текст передаются как аргументы. Эта функция иллюстрирует некоторые из возможностей обработки текстовых строк, заложенных в библиотеку STL:
|
Вслед за вызовом функции split() каждое найденное слово добавляется в алфавитный указатель с помощью следующего метода:
|
Метод addWord() гарантирует, что значения в карте слов не дублируются, если какое-либо слово встречается в одной строке дважды. Это достигается благодаря проверке записей, которые соответствуют ключу поиска. Каждая запись проверяется на совпадение номеров строк, и в случае совпадения запись в указатель не добавляется. Только если цикл проверки завершается без обнаружения записи с тем же номером строки, новая пара слово/номер строки добавляется в карту.
Последний шаг — распечатать алфавитный указатель. Это делается следующим образом:
|
Итератор циклически проходит по всем элементам, содержащимся в списке слов. Каждое новое слово порождает новую строку вывода; следующие за словом номера строк разделяются пробелами. Если, к примеру, на входе задан текст
|
то на выходе будут напечатаны слова от «best» до «worst»:
|
Мы отмечали, что во многих отношениях библиотека STL не является объектно-ориентированной. Скорее, она написана под воздействием функционального программирования. Означает ли включение STL в список стандартных библиотек C++, что объектно-ориентированное программирование выходит из моды?
Безусловно, нет. Объектно-ориентированные техники проектирования и программирования не имеют себе равных при разработке больших сложных систем. В большинстве задач программирования ООП будет оставаться главенствующим. Однако разработка STL (и не только) показывает желанные признаки того, что сообщество объектно-ориентированных программистов признает, что не все идеи должны иметь выражение в объектно-ориентированном стиле, равно как и не все проблемы обязаны решаться с помощью объектно-ориентированной техники.
Упражнения
Сайт создан в системе uCoz